There is a well known rule of thumb among microservices advocates that you should never share a database between microservices. This rule is, in my humble opinion, categorically wrong and still in most cases right. Software architecture is all about making trade-offs and so, anyone that considers themselves an architect should not take such rules at face value. This blog post is all about the trade-off.
Disclaimer: Opinions are my own and do not represent official company policy.
“Never share a database” is an ancient wisdom that comes from a time and place before the widespread proliferation of event-driven microservices, a good 20 years ago, when dinosaurs roamed the earth and it was customary to have monolithic “integration databases”. We talk about “integration” when we want to make data or functionalities from one application available to another. The integration database does this simply by letting applications access each other’s private data, perhaps through a single shared schema that was centrally designed or multiple schemas each suiting the “owning” application. Some examples where a shared database may be used in a microservice architecture are: product data used by many recommendation services in an online shop, a queue filled by one service and emptied by another, a product details page that has to aggregate information from many sources (product description, reviews, pricing, available stock).
Veterans tell us war stories by the campfire about all the bad things that can happen if we do this:
- A centrally designed schema will by owned by everyone and suite no one
- Separate schemas for each application will have an impedance mismatch between them. Domain-driven design has taught us that there is hardly ever agreement over the meaning of terms across different contexts.
- Applications that expose their own data schema to the outside world suddenly have to deal with schema evolution beyond their own control
- The same database technology has to be used by all for a dataset, even if there are radically different requirements for accessing it (some might need strong transactionality, others may need high read scalability)
- Noisy neighbors can affect the performance of other applications
- The central database server becomes a single point of failure for all applications
As we can see, there is some merit to the rule. I have personally experienced all of those problems.
Alternatives to sharing a relational database #
Obviously, not “integrating” and never sharing anything is not a realistic option. There are always use-cases that span more than one independent “service” no matter how large you try to make your service to avoid this; perhaps it is another whole company that gets acquired long after you came up with your perfect architecture and now needs to be integrated with the rest. We have seen the problems with the shared relational database and we are horrified. So what other options are there?
- Bespoke API: The owning microservice can provide an API (JSON-HTTP, GraphQL, gRPC, whatever) that allows other microservices to query its data or insert data.
- Event-driven data integration: Some kind of event log (Kafka usually) is used to disseminate changes in the data set to all interested listeners.
- In the “event sourcing” pattern, the owning microservice writes directly to the event log and then listens to the event log to update its own read model. The event log is the authoritative data source.
- In the “event-carried state transfer” pattern, the owning microservice writes to its database and transactionally also publishes a change event to the event log (via the outbox pattern for example). The private database is the authoritative data source and the event log is only derived from it
Both alternatives address some of the problems mentioned above, but not all of them. Primarily they achieve one important thing, the separation of the internal data model from the public interface, but don’t improve much on other aspects: HTTP calls on the public API translate directly to queries in the private database, leading to exactly the same problems with noisy neighbors and single points of failure. In fact, I would be willing to bet that the bespoke custom API is much much less reliable than a database server that has been battle tested for decades. Kafka clusters are similarly vulnerable to multitenant resource contention and don’t kid yourself: All Kafka consumers need to establish a synchronous TCP connection to the cluster. When the cluster is down, any reader will similarly be down. Kafka is not automatically more “asynchronous” and “high availability” than Postgres would be.
What is a database anyway? #
I have spent so many words explaining to you the dangers of shared databases, but it turns out that the alternatives aren’t all that much better and suffer from many of the same problems. Well, that is because they also are shared databases.
What is it that makes a database? A database holds data, hopefully in a durable way, and it allows you to query that data somehow. Both a microservice with REST API and a Kafka cluster fit that description. With the implementation of a bespoke API for data integration, your own microservice essentially becomes a custom domain-oriented database that only allows a few use-case specific queries. Kafka is a log-oriented database that optimizes for sequential reading, in contrast to the more flexible indices in a relational database (you can still submit arbitrary kSQL queries to Kafka, but a whole table scan will have to be performed every time). There are many other types of databases with various querying capabilities: document-oriented, graph-oriented, key-value, time-series, vector-search, full-text search, etc. etc. There is no reason to exclude our own microservice or Kafka from that definition.
What makes bespoke APIs and particularly event-carried state transfer with Kafka nonetheless often fare better in practice than a shared relational database is not so much what those designs can do, but what they cannot do! Both setups are much more complicated and ad-hoc than simply connecting another client to the database, forcing lazy programmers to not take the shortcuts that make shared relational databases problematic:
- Both force publisher and consumer to separate their private data from the public interface and come up with a sensible schema that can be evolved independently
- Both prevent consumers from writing into the data owned by someone else because it was “convenient” and “KISS” and “the ticket had to be finished before end of sprint”
- An event-driven approach further improves independence over a bespoke synchronous API because the event database (Kafka) has such crappy querying capabilities that consumers are forced to stand up their own database for querying that is populated asynchronously from the data integration channel (Kafka topic). Each consumer will use the database technology that is most suitable for its use case and is no longer synchronously coupled to the availability of the integration channel (Kafka or API microservice) or able to impact the performance of other applications
CQRS #
Command Query Responsibility Segregation (CQRS) is the magical keyword that solves the independence problem of data integration. It describes a strict separation of the write model (command) and read model (query). In other words: the responsibility of recording state changes and the responsibility of querying the state are separated in some way. The write model and read model can be separate data types for the same database (as when using the DDD “aggregate” tactical pattern for writing combined with thin DTOs for reading) or they can be entirely separate databases. Obviously, a “write model” is not exclusively for writing, since data that is never read would be useless. Analogously, the “read model” has to have been written down at some point to be able to read it. The key point of the CQRS pattern is to realize that writing and reading use cases often pose different requirements on the data model / database. In the context of inter-microservice data exchange, the essential differing requirement is that the write model is authoritative on what kind of data is saved at all as the result of some business process and thus what kind of data is available to be shared with other microservices. The write model has to anticipate the needs of unknown consumers. The read model, on the other hand, only ever has an impact on the one microservice that reads it and should ideally be custom to every microservice to satisfy its specific needs. Allow me to illustrate the concept with an example: We implement a “pricing” microservice in an online shop with the following functional requirements:
- Serve an HTML snippet displaying the current price of a product
- Provide a user interface to adjust product prices
- Validate new price to be not too high or to low
For these use cases, it is sufficient to be able to query the current price (requirement for the pricing microservice’s internal read model). However, if this pricing microservice wants to share its pricing data with other microservices, then those other microservices may also be interested in the history of pricing changes. A product price always changes for a reason. Perhaps due to a site-wide temporary discount, because the product is going out-of-season or because procurement has become more expensive. At any point where state changes are made to the pricing data, we need to save the history of changes and the business event that triggered it, to be able to share this data later with other microservices. Those are the requirements for the write model.
One thing that usually gets lost when using a combined read and write model is the temporal nature of changes. Unless there is an explicit requirement for auditing, our default approach is to simply overwrite old data in the table when changes are made, since most reading use cases are only interested in the current state of the data and not how it got there. But a “change” is always a progression from one state into another; any write to the data is necessarily the result of some kind of business event that happened at a specific time, for a specific reason (unless you are merely importing a dataset from another source). Thus, the natural representation of the data at the point of writing (with no consideration for reading) is an ordered log of business terminology events. It is simply a record of what happened and when, no more, no less.
Inter-microservice CQRS splits the data store into an event-based write model at the producer and many materialized read models at each consumer, optimized for their specific queries. It is the pattern that allows us to have the greatest independence, not only abstracting the private data model of the owner microservice, but also severing all direct runtime dependencies between the consumer microservices and the data source. In that way, each microservice can develop its own use cases completely independently without being concerned about compatibility of schema changes, availability of data sources or adverse effects on other users of the database.
Responsible sharing of relational databases #
Schema abstraction, CQRS and event-carried state transfer are not patterns that are mutually exclusive with a simple old relational database. Let me show you how we can implement quite similar constructs entirely within Postgres and achieve a similar effect, with far less complexity than running an additional Kafka cluster or implementing a bespoke API for every query operation from other microservices.
Data model abstraction #
Hiding the private data model behind a public interface is very easy. Just use a view:
CREATE TABLE users_private (
user_id int NOT NULL PRIMARY KEY,
first_name text NOT NULL,
last_name text NOT NULL,
age int NOT NULL
);
INSERT INTO users_private (id, first_name, last_name, age)
VALUES
(1, 'Bob', 'Barker', 99);
CREATE VIEW users_public AS
SELECT
user_id AS user_id,
CONCAT(first_name, ' ', last_name) AS name,
age AS age
FROM users_private;
GRANT SELECT, TRIGGER, REFERENCES ON users_public to PUBLIC;
For an event-based write model we could also use a public table as the source of truth (i.e. do event-sourcing) and a view for the private read model of the owner:
CREATE TABLE user_events_public, (
event_id int NOT NULL PRIMARY KEY,
user_id int NOT NULL,
name text,
age int,
last_changed timestamptz NOT NULL,
operation text NOT NULL
);
GRANT SELECT, TRIGGER, REFERENCES ON user_events_public to PUBLIC;
INSERT INTO user_events_public (event_id, user_id, name, age, last_changed, operation)
VALUES
(1, 1, 'Bob Barker', 99, NOW(), 'USER_SIGNED_UP'),
(2, 2, 'Alice Abbott', 88, NOW(), 'USER_SIGNED_UP'),
(3, 2, NULL, NULL, NOW(), 'USER_DELETED_ACCOUNT');
CREATE VIEW users_private AS
SELECT
SPLIT_PART(name, ' ', 1) AS first_name,
SPLIT_PART(name, ' ', 2) AS last_name,
age AS age
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_id DESC) AS row_num
FROM user_events_public
) AS ordered_by_user
WHERE row_num = 1
AND name IS NOT NULL
AND age IS NOT NULL;
If aggregating the events into their latest state on each read is too expensive, we could simply have the application insert into both tables within the same transaction or use a trigger to make an auto-updating materialized view:
CREATE FUNCTION do_update_users_private() RETURNS trigger AS $do_update_users_private$
BEGIN
IF NEW.name IS NULL THEN
DELETE FROM users_private
WHERE user_id = NEW.user_id
END IF;
IF NEW.name IS NOT NULL THEN
INSERT INTO users_private (user_id, name, age)
VALUES (NEW.user_id, NEW.name, NEW.age)
ON CONFLICT (user_id) DO UPDATE
SET
first_name = SPLIT_PART(EXCLUDED.name, ' ', 1),
last_name = SPLIT_PART(EXCLUDED.name, ' ', 2),
age = EXCLUDED.age
END IF;
RETURN NULL;
END;
$do_update_users_private$ LANGUAGE plpgsql;
CREATE TRIGGER update_users_private
AFTER INSERT OR UPDATE ON user_events_public
FOR EACH ROW
EXECUTE FUNCTION do_update_users_private();
Performance Isolation #
The second major problem in need of adressing is that of noisy neighbours in the multi-tenant database system. A connection limit per tenant can be set within the database or within pgbouncer to reduce the performance impact of request bursts. However, this is neither very efficient nor particularly effective at isolating applications from eachother, as the most problematic shared resource shortages tend to be caused by few expensive queries and not a burst of many cheap ones. In the typical event-driven microservices architecture, this is solved by populating a database instance per microservices with events from a Kafka topic, as the following diagram shows:
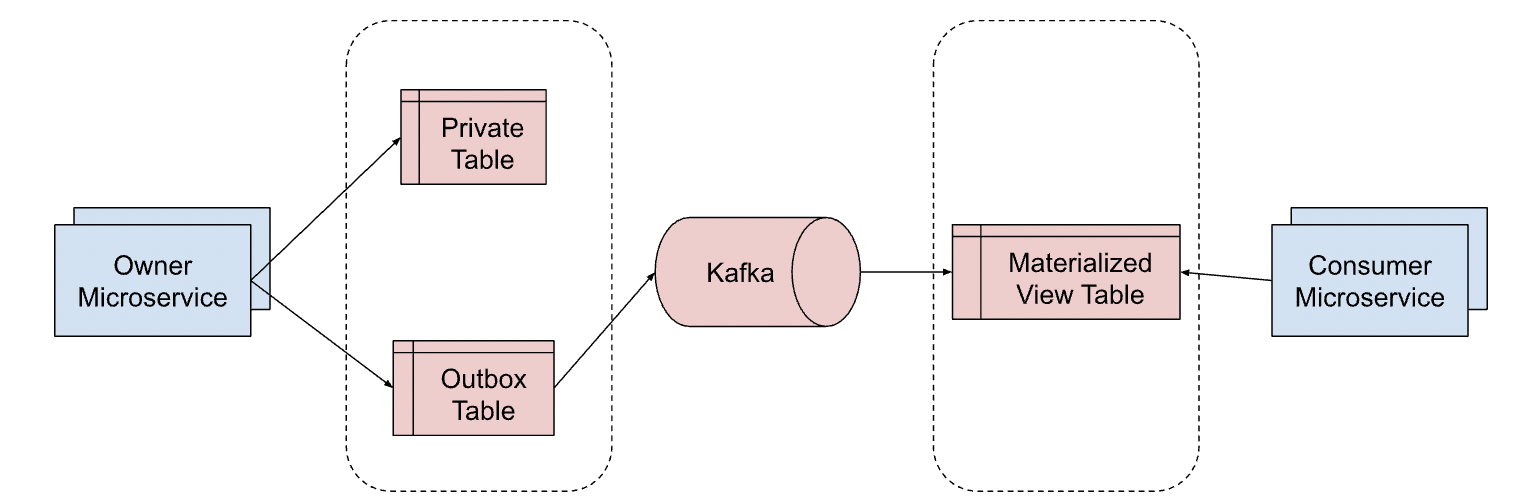
— System architecture of event-carried state transfer pattern —
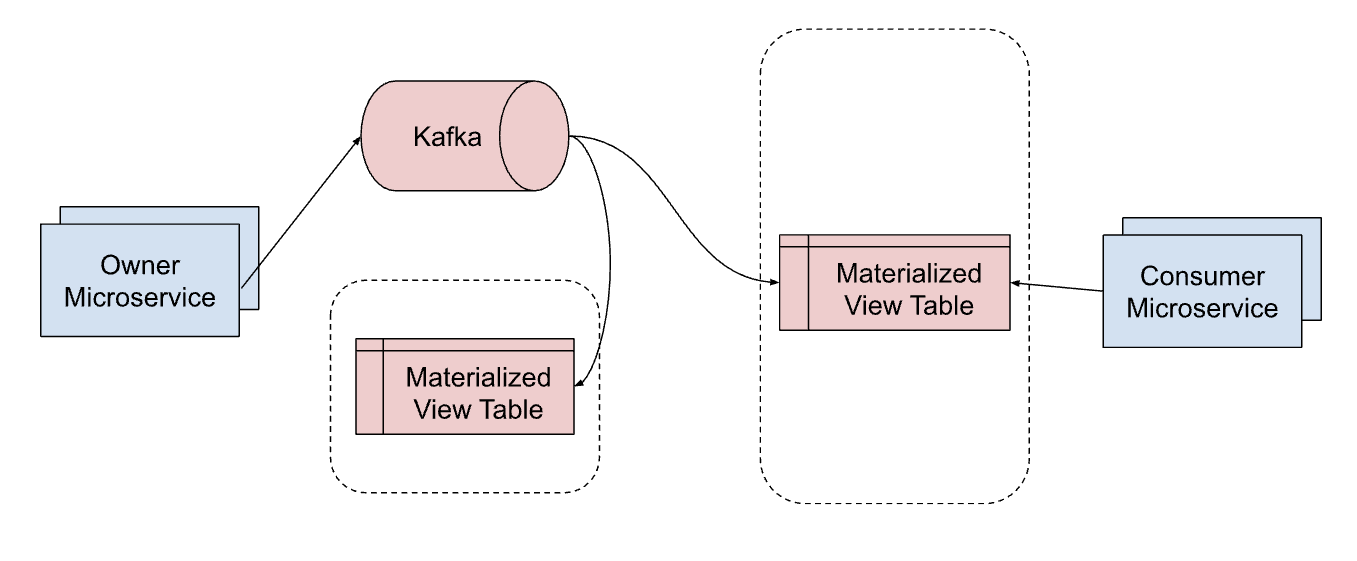
— System architecture of event sourcing pattern —
And here is a diagram of asynchronous logical streaming replication between two Postgres servers:
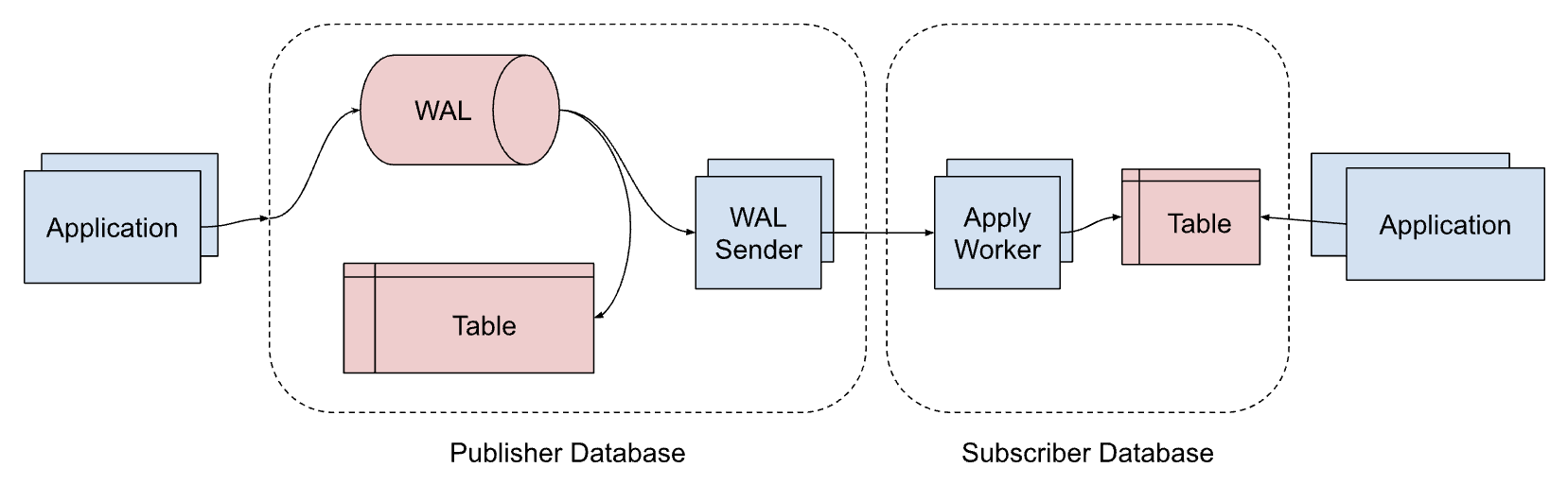
— System architecture of asynchronous logical streaming replication in Postgres —
Looks familiar doesn’t it? Every change is first written to the Write-Ahead-Log (WAL) for durability, then applied in the local table and at the same time new entries in the WAL are logically decoded and then streamed as change events to the other database server, where they will be applied to a table. This mirrors the event-sourcing setup with Kafka almost exactly, but entirely within Postgres, and shows how we may implement data integration with an independent Postgres instance per microservice, without having to rely on Kafka for the exchange. Postgres handles everything for us (except for synchronization of schema changes).
First we have to create a publication for one or more tables that need to be replicated on the database server of the owner microservice. Publications are somewhat comparable to a Kafka topic.
ALTER SYSTEM SET wal_level = logical;
SELECT pg_reload_conf();
CREATE PUBLICATION users_publication FOR TABLE users_public;
Publications can contain filters to publish only certain rows or columns, or only certain change events. Importantly, a publication can only replicate tables not views or DDL. In consequence, the replicated object that is the public interface to our data must be a table. We can not use views here to abstract our private data model. Also, the schema of the table and any changes to the schema must be exchanged through another channel, but that’s the same for Kafka.
Next, a subscription must be created on the database server of the consumer microservice, to receive the replication events. We also need to create the users_public table manually in the consumer database, because the DDL is not replicated:
CREATE TABLE users_public (
user_id int NOT NULL PRIMARY KEY,
name text NOT NULL,
age int NOT NULL
);
CREATE SUBSCRIPTION users_subscription
-- insert connection info to the publisher database here
CONNECTION 'host=192.168.1.50 port=5432 user=foo dbname=foodb'
PUBLICATION users_publication;
And that’s it! New data will automatically arrive in the users_public table and the consumer microservice can query it in its own database however it wants, without adverse effects on other microservices.
Of course, this solution does not address the final problem: All microservices are still limited to Postgres and can not use other database technologies that may be more appropriate to their use case. There are ways to replicate logical data changes from the WAL directly to another database technology without having Kafka as an intermediary (using Debezium Server for example), but at that point it is probably sensible to standardize on Kafka as the default data exchange. Nontheless, we have shown that you can go quite far with humble Postgres and do not have to go all the way to big-tech infrastructure to implement a good microservice architecture, if you know what you’re doing.
Recap #
- “Never share a database” is wrong because practically everything that shares data is a database; there is no alternative.
- “Never share a database” is still a useful rule of thumb because it nudges you towards other integration patterns that coincidentally don’t support the problematic implementation shortcuts.
- Separating the public interface from the internal data model is the most important factor for responsible data sharing
- With some ingenuity, many classical problems of the “shared database” can be mitigated, even the event-carried state transfer pattern can be implemented completely in Postgres.
- Know the trade-offs and know when it is safe to share a relational database between microservices or when it is not.
Kommentare