Reverse proxies often are the key component in a web platform, be it eCommerce, B2B or anything else. Hence, they need to be rock solid. In my experience, reverse proxy outages only seldomly occur due to bugs in the proxy software itself, but rather from misconfiguration. You frequently have to modify reverse proxy configuration according to business needs. On each such change, you want to have a high degree of certainty that you don’t introduce regressions or security issues. After all, each such regression might result in degraded user experience or an outright outage of your site(s). In the context of microservices, integration testing is one of the building blocks for preventing regressions or undesired behavior. They are less often used for infrastructure components like reverse proxies. Nonetheless, they can be invaluable in preventing outages, which are often especially costly in reverse proxies.
This blog post outlines a setup we used to perform acceptance tests on the reverse proxy in front of a large eCommerce platform. Changes to this proxy were contributed by a large number of stream-aligned teams and rolled out using a CI/CD process. These teams were owners of the self-contained systems (SCS) which were being proxied, but did not own the reverse proxy itself. While the setup specifically used nginx, the pattern described here should mostly be applicable to other reverse proxies.
The issue at hand #
The proxy was responsible for TLS offloading, setting client identifier and X-Forwarded headers, and performing some basic routing based on the request URL. Most importantly though, we utilized nginx’s Server Side Includes (SSI) feature to integrate micro frontend components provided by different stream-aligned teams. Additionally, nginx also reverse-proxied external services, such as link bait content pages.
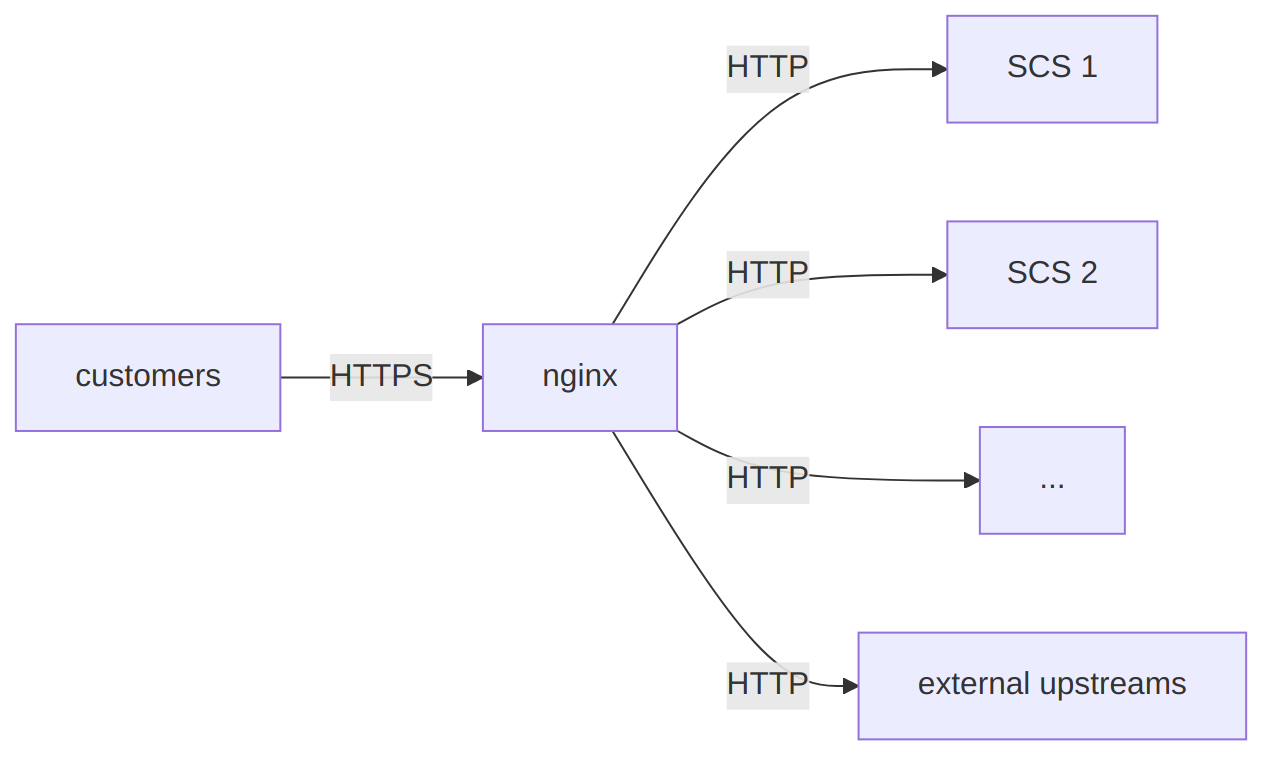
What made this setup challenging was the rather large number (>50) of tenant/country/language combinations under the umbrella of the eCommerce platform. Each of these combinations mostly shared the same configuration, but also needed a slightly different set of settings (such as host names, language-specific path prefixes and tenant/country identifier headers sent to the upstream services), and routing rules. In order to keep the configuration manageable, we decided to use a templating engine to generate the nginx configuration files.
The reverse proxy was managed by one of the stream-aligned teams (there was no dedicated platform team, which otherwise could be responsible). This team was responsible for the configuration of the proxy, but not for the configuration of the upstream services. The latter was the responsibility of the stream-aligned teams. The other stream-aligned teams routinely provided merge requests to the reverse proxy team to add or modify routing rules in the nginx configuration. This means that configuration was often contributed by people not well-versed in the specifics of nginx configuration. Combined with the large number of tenant/country/language combinations, this had the potential for introducing errors in the configuration. For example, if a location block were to be added to the wrong server block, or if its path prefix were incorrect, the reverse proxy might start routing requests to the wrong upstream service. Moreover, nginx configuration has some notorious pitfalls, such as the if and try_files directives, which can lead to unexpected behavior and/or security issues. And quite frankly, the setup was inconvenient to the stream-aligned teams, as predicting whether their change sets would lead to their desired outcome.
We therefore needed a testing setup which would:
- allow stream-aligned teams to test their merge requests against a maintainable set of test cases
- make it easy for stream-aligned teams to contribute tests
- allow the team which owned the reverse proxy to have confidence when rolling out changes
- comprehensively test for security issues and regressions
- run quickly to reduce CI/CD runtime and speed up iteration cycles
Security Testing #
We used gixy to check for common security pitfalls in our templated nginx configuration files. Gixy runs static analysis on your configuration and notifies you in case of common misconfigurations. This helps in preventing server-side request forging (SSRF) or denial-of-service attack vectors. Running it was very painless, and I can thoroughly recommend it. Just a word of caution: since our resulting configuration was rather voluminous, a gixy run would take several minutes.
Acceptance testing #
The tests #
The setup allowed us to write tests like this (example.com would have been replaced with a production domain of ours, of course):
def test_routing():
# When a route owned by the team responsible for SCS A is requested
res = Http.get(f"https://example.com/scs-a/foo")
# Then the reverse proxy forwards the request to the scs-a host
assert "HTTP_HOST=scs-a"
def test_referrer_header_should_be_retained():
# When there is a request with the Referer HTTP header set
headers = {
"Referer": "example.com"
}
res = Http.get(f"https://example.com/", headers=headers)
# Then the header should be forwarded to the upstream
assert 'HTTP_REFERER="example.com"' in res.text
def test_server_side_includes_should_be_active():
# When there is a request for a page for which SSI is active
res = Http.get(f"https://example.com/ssi-active/some-page-with-ssi")
# Then the SSI tag is resolved and replaced with the SSI fragment
assert res.text.strip() == "SSI: fragment-content"
def test_server_side_includes_should_not_be_active():
# When there is a request for a page for which SSI is not active
res = Http.get(f"https://example.com/ssi-inactive/some-page-with-ssi")
# Then the SSI fragment is not resolved and returned verbatim
assert res.text.strip() == "SSI: <!--#include virtual=\"/fragment/ssi-fragment\" -->"
# Note: this was a much larger and more elaborate data set in practice
production_www_domains: ["www.tenant1.example.com", "www.tenant2.example.com"]
@mark.parametrize("domain", production_www_domains)
def test_an_upstream_404_should_result_in_global_404_page(domain):
# When there is a request to an upstream which returns an HTTP 404
res = Http.get(f"https://{domain}/force-http-404")
# Then the reverse proxy retains this status code
assert res.status_code == 404
# And replaces the upstream response body with the global 404 page
assert res.text.strip() == "global 404 page"
Below, I am going to explain how this worked under the hood.
The test setup #
We wanted to perform the acceptance tests on a running instance of the reverse proxy, to be as close as possible to the final deployment state. Actually starting nginx would also implicitly verify that the configuration was valid, because it fails to start up on invalid configuration. We decided to use a docker-compose setup to spin up a local integration setup. This setup contained several components besides the reverse proxy itself:

This is a simplified version of the resulting docker-compose setup:
services:
# The reverse proxy, containing the production configuration
nginx:
build:
context: .
dockerfile: Dockerfile # The production Dockerfile for the reverse proxy
ports:
- "127.0.0.1:80:80"
- "127.0.0.1:443:443"
volumes:
# mock certificates so nginx may start up
- ./test/ssl:/ssl/tenant-a:ro
- ./test/ssl:/ssl/tenant-b:ro
links:
# Links provide DNS aliases pointing to the mock-server container
- mock-server:scs-1
- mock-server:scs-2
- mock-server:www.external.example.com
- mock-server:www.something-else.example.com
extra_hosts:
# In production, we used a CoreDNS instance to resolve upstreams.
# Here, we use the docker internal DNS resolver instead.
- "dns-server:127.0.0.11"
# Mock upstream for testing, which e.g. responds with specified error codes,
# upstream content, or returns the request URI and headers as a response
mock:
hostname: mock-server
build:
context: ./test/containers/mock-server
dockerfile: Dockerfile # see below for content
depends_on:
- echo-fcgi
# FCGI process used by the mock server, which renders request variables
# (headers etc.) as a response
echo-fcgi:
build:
context: ./test/containers/echo-fcgi
dockerfile: Dockerfile
networks:
default:
# test network is set to 'internal' so no traffic escapes the test jig.
# Otherwise, since the nginx configuration might reference externally
# owned domains, you might involuntarily issue requests against these
# external systems during testing.
# If you just want to run the test jig for manually testing, you can
# remove this section.
internal: true
driver: bridge
Some notes on the setup:
nginx #
The nginx container was built from the production Dockerfile. This ensured that the nginx configuration was as close to production as possible. We had volume mounts for the TLS certificates. The /test/ssl directory contained a single self-signed certificate. By mounting it multiple times to the subdirectories where the production certificates would be, we could provide nginx with the necessary certificates to start up.
Note: the setup as we built it did not verify that the correct certificates were used. It would not be difficult to include this, though. You’d just need to generate certificates for each tenant domain and add them to the test trust store of the test container.
The extra_hosts directive was used to provide DNS aliases for the upstream services. All these aliases pointed to the mock-server container, which was used to emulate the upstream services. In production, we used a CoreDNS instance to resolve upstreams. Here, we used the docker internal DNS resolver instead.
Note: nginx by default only does DNS resolution at startup. In production, this can not only lead to stale resolutions, but also to a startup failure if the upstream name is unavailable at startup. Therefore, we configured nginx to dynamically resolve upstreams using the
resolverdirective. This has recently been made more convenient to do by the introduction of theresolveparameter.
mock-server #
The mock-server container was used to emulate the upstream services. It was also implemented using an nginx, but with an entirely different configuration. The mock-server container was used to test the routing rules in the nginx configuration. It could be configured to respond with specified error codes, upstream content, or return the request URI and headers. In order to do this, it had locations like this:
# By default, echo request content as a response, using the echo-fcgi container
location / {
fastcgi_pass echo-fcgi:9000;
fastcgi_param SCRIPT_FILENAME /srv/cgi/printenv;
fastcgi_param REQUEST_URI $request_uri;
fastcgi_param SCHEME $scheme;
}
# Return specific test files from the /srv/www directory of the mock-server container
location ~ ^.*\.(js|css|html) {
root /srv/www;
rewrite ^.*\.(js|css|html) /test.$1 break;
}
# Return specific status codes according to the request path
location ~ .*/force-http-403 {
return 403;
}
location ~ .*/force-http-404 {
return 404;
}
# Page with SSI upstream
location ~ ^.*/page-with-ssi {
root /srv/www;
rewrite ^ /page-with-ssi.html break;
}
# page with broken SSI upstream
location ~ ^.*/page-with-ssi-force-http-(?<code>[0-9]+) {
add_header Content-Type text/html; # SSI only works if the content-type is set correctly
return 200 "SSI: <!--#include virtual=\"/fragment/force-http-$code\" -->";
}
Where /srv/www/page-with-ssi.html contained a basic SSI directive:
SSI: <!--#include virtual="/fragment/ssi-fragment" -->
echo-fcgi #
The echo-fcgi container was used to render request variables (headers etc.) as a response.
FROM debian:12-slim
RUN \
DEBIAN_FRONTEND=noninteractive \
apt-get update && \
apt-get -y install fcgiwrap
COPY printenv /srv/cgi/printenv
RUN chmod +x /srv/cgi/printenv
USER root
CMD ["spawn-fcgi", "-p", "9000", "-n", "/usr/sbin/fcgiwrap"]
Where the printenv script was a small perl script:
#!/usr/bin/perl
# ***** !!! WARNING !!! *****
# This script echoes the server environment variables and therefore
# leaks information - so NEVER use it in a live server environment!
# It is provided only for testing purpose.
use strict;
use warnings;
print "X-Application-Timing: 235\n";
print "Content-type: text/plain; charset=iso-8859-1\n\n";
foreach my $var (sort(keys(%ENV))) {
my $val = $ENV{$var};
$val =~ s|\n|\\n|g;
$val =~ s|"|\\"|g;
print "${var}=\"${val}\"\n";
}
Running the tests #
The tests were written in Python, using pytest and requests. We chose Python because it is simple to use, and is known by many developers. Of course, you could use any testing framework you like. The tests were run in a container, which was attached to the docker network created by the above docker-compose setup:
FROM python:3.12
# Provide a working directory with correct permissions
USER root
RUN mkdir -p /test && chown -R python: /test
USER python
WORKDIR /test
ENV PATH="/home/python/.local/bin:${PATH}"
# Install the test dependencies (this was done using a dependency management tool)
RUN pip3 install --user pytest pytest-xdist requests
# Copy the test files
COPY --chown=python:python . .
ENV PYTHONWARNINGS="ignore:Unverified HTTPS request"
ENV PYTHONPATH="/test:${PYTHONPATH}"
ENTRYPOINT ["pytest"]
# Run tests concurrently and verbosely
CMD ["-n", "16", "-vv"]
In order to have the tests run against the test setup, we used the requests library to provide a simple HTTP client. This client rewrote the requests so that they were always running against the nginx container. This enabled us to use the final production domains in the tests, which made them easier to understand.
import requests
class Request:
def __init__(self, url, **kwargs):
proto, domain_and_path = url.split("://", 1)
domain = domain_and_path.split("/")[0]
path = "".join(domain_and_path.split("/", 1)[1:])
# Direct any requests to the nginx container, but set the host header to the domain
# which was requested.
self.headers = kwargs["headers"] if "headers" in kwargs else dict()
self.headers["host"] = domain
# While running in the docker network from the docker-compose file,
# the DNS name "nginx" resolves to the nginx container
self.request_url = "{}://nginx/{}".format(proto, path)
# Remove the unmodified headers from the kwargs dict, so that we don't
# forward them to the requests client (see below)
self.kwargs = kwargs
if "headers" in self.kwargs:
del self.kwargs["headers"]
class Http:
@staticmethod
def get(url, params=None, allow_redirects=False, **kwargs):
req = Request(url, **kwargs)
# Note that we use verify=False here, because we used self-signed certificates and did not
# want to bother with adding them to the trust store.
return requests.get(req.request_url, params, allow_redirects=allow_redirects, verify=False, headers=req.headers,
**req.kwargs)
@staticmethod
def post(url, params=None, allow_redirects=False, **kwargs):
req = Request(url, **kwargs)
return requests.post(req.request_url, params, allow_redirects=allow_redirects, verify=False, headers=req.headers,
**req.kwargs)
And this is how it all came together to make the tests from before possible:
def test_routing():
# This request is rewritten by the `Http` class to redirect it to the `nginx` container.
# nginx processes the request, and forwards it to the upstream, setting the
# `Host` header in the process. The mock-server then returns a response body with all
# the HTTP headers it sees.
res = Http.get(f"https://example.com/scs-a/foo")
# Therefore, we can assert on what the mock-upstream has seen. In this case, we
# assert the host header, which tells us the server to which the reverse proxy would
# have forwarded the request.
assert "HTTP_HOST=scs-a"
def test_referrer_header_should_be_retained():
# This is basically the same test as above, but with a custom header set by the client
headers = {
"Referer": "example.com"
}
res = Http.get(f"https://example.com/", headers=headers)
assert 'HTTP_REFERER="example.com"' in res.text
def test_server_side_includes_should_be_active():
# The mock-server is configured to return a page with an SSI tag for this path.
# The upstream page content is 'SSI: <!--#include virtual=\"/fragment/ssi-fragment\" -->'
res = Http.get(f"https://example.com/ssi-active/some-page-with-ssi")
# If nginx is configured correctly, it is going to interpret the SSI tag, resolve the
# include and replace the tag with the response of the SSI fragment
assert res.text.strip() == "SSI: fragment-content"
def test_server_side_includes_should_not_be_active():
# This is the inverse of the test above. For the /ssi-inactive prefix we don't want
# nginx to parse the SSI tags
res = Http.get(f"https://example.com/ssi-inactive/some-page-with-ssi")
# This means that SSI tags are returned verbatim, without performing the include.
assert res.text.strip() == "SSI: <!--#include virtual=\"/fragment/ssi-fragment\" -->"
production_www_domains: ["www.tenant1.example.com", "www.tenant2.example.com"]
@mark.parametrize("domain", production_www_domains)
def test_an_upstream_404_should_result_in_global_404_page(domain):
# Again, the Http class redirects all these requests to the nginx container
res = Http.get(f"https://{domain}/force-http-404")
assert res.status_code == 404
assert res.text.strip() == "global 404 page"
As you can see, we were able to parametrize the tests to run against different tenant domains. This was very useful, as we could run the same test against all tenant domains, and thus ensure that the routing rules were correct for all of them. This was especially helpful when adding new tenant domains, as we could check the routing for the new domain without writing new tests. However, parametrizing the tests also led to a large number of test cases. This was not a problem, as we could use pytest-xdist to run the tests in parallel, which sped up the test run considerably.
Conclusion #
The setup described here allowed us to test the reverse proxy configuration both in a CI/CD pipeline and locally. The setup was very flexible, as we could easily add new test cases for new routing rules. It ran quickly, and afforded both the reverse proxy team and the stream-aligned teams a high degree of confidence when rolling out changes. Since the reverse proxy team could see both the implementation, and have the test cases as a specification, they could more easily infer the behavior which was to be introduced by the change set. The setup was also very useful for debugging, as developers could easily run the tests against a local instance of the reverse proxy, and directly see the results in the test output.
I realize that the setup described here won’t work for every project. Especially, now that the usage of Kubernetes ingress controllers is becoming more widespread, you might need to devise another method of verifying changes. For server-side rendering with includes, which are still widespread in micro frontend setups, I think the approach outlined above can be very useful. I hope that this post has given you some inspiration on how or whether to test your reverse proxy configuration. I would be very interested in hearing your approach to similar challenges :)
Photo credit: Daniel Andrade
Kommentare