Claude Code bringt KI-Assistenz direkt in die lokale Entwicklungsumgebung. Während Claude Code standardmäßig Anthropics Cloud-Dienste nutzt, bietet die Integration mit AWS Bedrock zusätzliche Flexibilität und Kontrolle über die verwendeten Modelle. In diesem Artikel zeige ich anhand unserer konkreten inoio-Konfiguration, wie du Claude Code mit AWS Bedrock einrichtest und nutzt.
Was ist Claude Code? #
Claude Code ist Anthropics offizielles CLI-Tool, das KI-gestützte Softwareentwicklung direkt im Terminal ermöglicht. Es bringt intelligente Code-Analyse für komplexe Codebases mit sich, ermöglicht automatisierte Code-Generierung von einzelnen Funktionen bis hin zu ganzen Features und unterstützt projektübergreifende Refaktorierung zur systematischen Verbesserung der Codequalität. Zusätzlich bietet es interaktive Debugging-Hilfe mit präziser Fehleranalyse und konkreten Lösungsvorschlägen.
Warum AWS Bedrock? #
AWS Bedrock ist Amazons verwalteter Service für Foundation Models, der Zugang zu verschiedenen KI-Modellen über eine einheitliche API bietet. Für Claude Code bedeutet die Bedrock-Integration erweiterte Kontrolle über die Modellauswahl, da neben verschiedenen Claude-Modellen auch andere Foundation Models wie etwa von Amazon, Meta oder Cohere verfügbar sind. Zusätzlich ermöglicht es regionale Kontrolle über die Datenverarbeitung, erfüllt unternehmensweite Compliance-Anforderungen und bietet direkte AWS-Abrechnung.
AWS-Konfiguration #
Das prinzipielle Vorgehen für die Bedrock-Integration ist in der offiziellen Anthropic-Dokumentation unter https://docs.anthropic.com/en/docs/claude-code/amazon-bedrock beschrieben. Hier dokumentiere ich eine konkrete Umsetzung, die als Referenz für dein eigenes Setup dienen kann.
AWS Account und API-Schlüssel #
Für das Setup benötigst du einen AWS-Account mit ausreichenden Rechten, um die benötigten Ressourcen zu erstellen. Ein Root-Account funktioniert immer, aber du kannst auch einen IAM-Benutzer mit entsprechenden Berechtigungen verwenden. Der erste Schritt besteht darin, dich mit deinem Account in die AWS-Konsole einzuloggen und anschließend zu den Bedrock API Keys zu navigieren.
In der Bedrock-Konsole erstellst du einen Long Term API Key, den du für die späteren Umgebungsvariablen benötigst. Dieser API-Schlüssel ist das Herzstück der Authentication zwischen Claude Code und AWS Bedrock. Kopiere den generierten Key sorgfältig, da er nur einmal angezeigt wird. Behandle diesen API-Schlüssel immer wie ein Passwort!
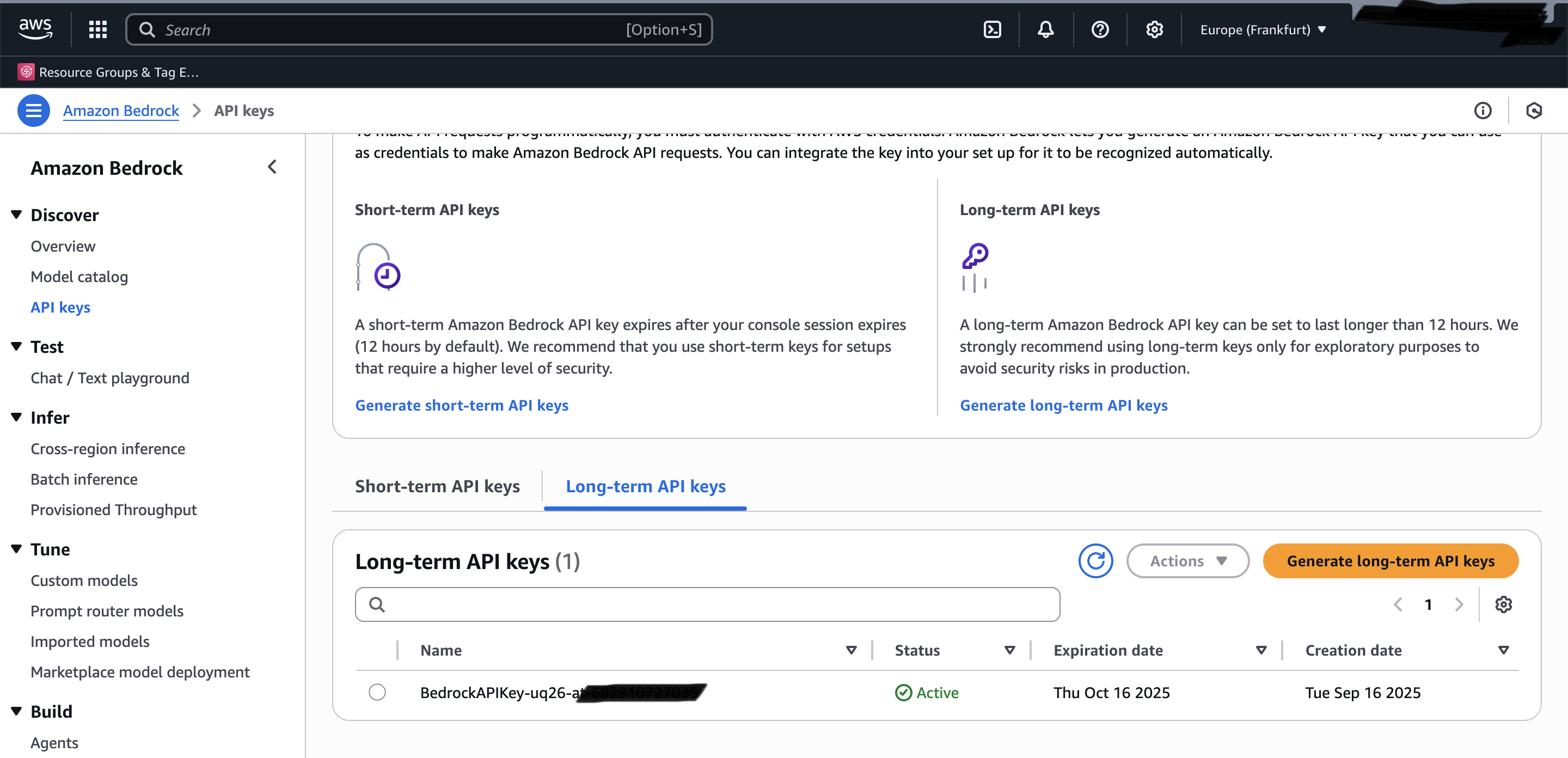 AWS Bedrock API Keys Übersicht mit Long-term API Keys
AWS Bedrock API Keys Übersicht mit Long-term API Keys
Konfigurationsskript erstellen #
Mit dem API-Schlüssel kannst du nun das Konfigurationsskript erstellen. Erstelle eine Datei namens bedrock.sh und füge folgende Konfiguration ein:
export AWS_BEARER_TOKEN_BEDROCK=<-- INSERT TOKEN HERE -->
# Enable Bedrock integration
export CLAUDE_CODE_USE_BEDROCK=1
export AWS_REGION=eu-central-1 # or your preferred region
# Optional: Override the region for the small/fast model (Haiku)
#export ANTHROPIC_SMALL_FAST_MODEL_AWS_REGION=us-east-1
# Using inference profile ID
export ANTHROPIC_MODEL='eu.anthropic.claude-sonnet-4-20250514-v1:0'
export ANTHROPIC_SMALL_FAST_MODEL='eu.anthropic.claude-3-haiku-20240307-v1:0'
# Using application inference profile ARN
#export ANTHROPIC_MODEL='arn:aws:bedrock:us-east-2:your-account-id:application-inference-profile/your-model-id'
# Optional: Disable prompt caching if needed
#export DISABLE_PROMPT_CACHING=1
# Recommended output token settings for Bedrock
export CLAUDE_CODE_MAX_OUTPUT_TOKENS=4096
export MAX_THINKING_TOKENS=1024
Ersetze den Platzhalter <-- INSERT TOKEN HERE --> durch deinen tatsächlichen API-Schlüssel.
Benutzerberechtigungen konfigurieren #
Beim Anlegen des API-Schlüssels wird automatisch ein dazugehöriger Benutzer in AWS IAM erstellt. Dieser Benutzer benötigt entsprechende Berechtigungen für Bedrock-Services. Navigiere zur IAM-Konsole und suche den neu erstellten Benutzer. Unter “Permissions” fügst du die Berechtigung “AmazonBedrockFullAccess” hinzu, die alle notwendigen Rechte für die Bedrock-Nutzung umfasst.
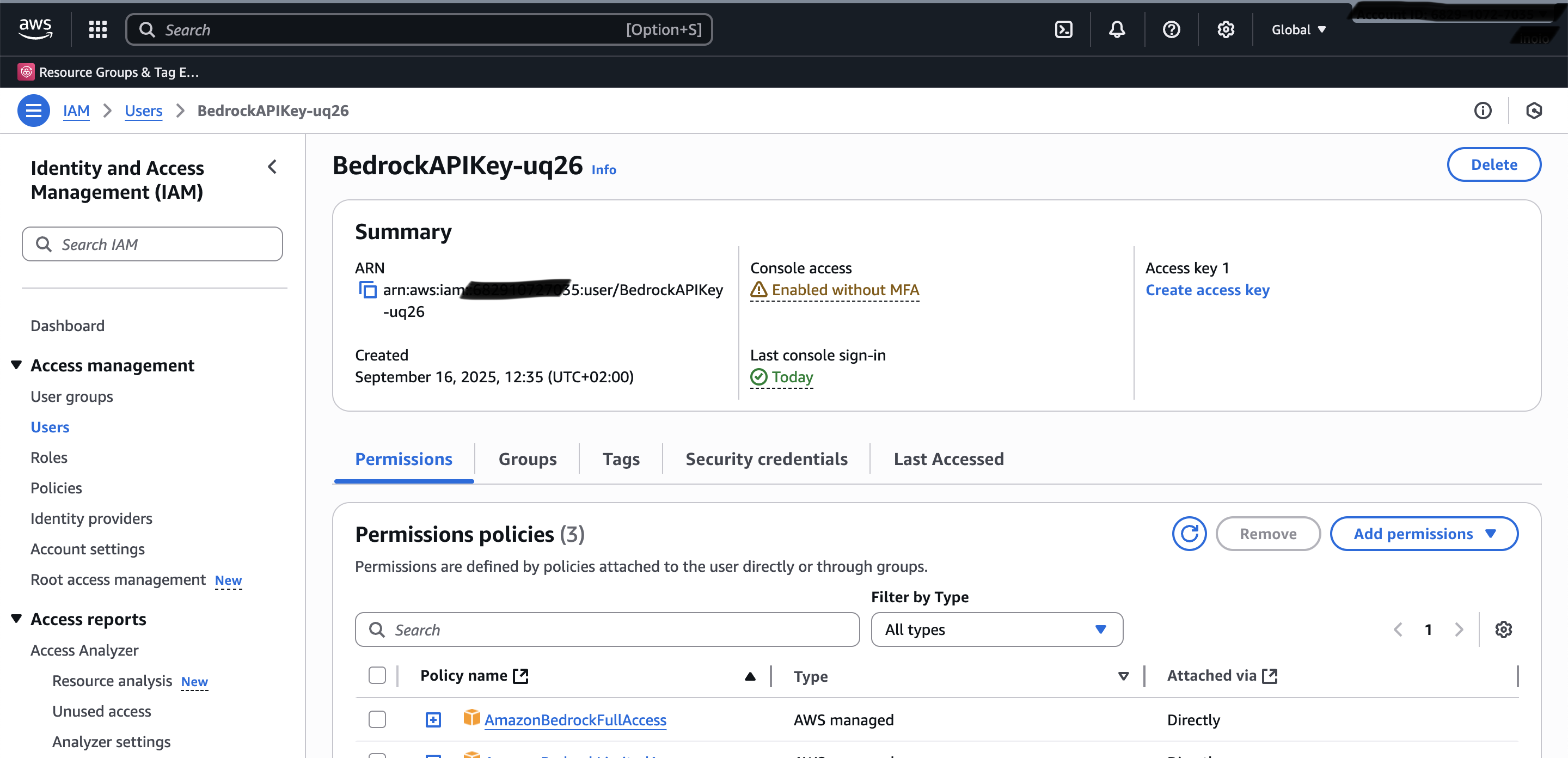 IAM-Benutzer mit AmazonBedrockFullAccess Berechtigung
IAM-Benutzer mit AmazonBedrockFullAccess Berechtigung
Console-Zugang einrichten #
Ein wichtiger Schritt, der oft übersehen wird, ist die Einrichtung des Console-Zugangs für den erstellten Benutzer. Du benötigst diesen Zugang mindestens einmal, um als dieser Benutzer die Modell-Zugangsrechte beantragen zu können. Navigiere zu den “Security Credentials” des Benutzers und aktiviere “Console Access”. Vergib ein sicheres Passwort, das du dir notierst.
Modell-Zugriffsrechte beantragen #
Nun loggst du dich mit dem neu erstellten Benutzer in die AWS-Konsole ein und navigierst zu Bedrock. Unter “Configure and learn” findest du den Bereich “Model access”. Hier beantragst du Berechtigungen für alle Modelle, die du nutzen möchtest - neben Claude-Modellen stehen auch andere Foundation Models verschiedener Anbieter zur Verfügung. Dieser Genehmigungsprozess dauert in der Regel etwa fünf Minuten. Refreshe die Seite gelegentlich, um den Status zu überprüfen.
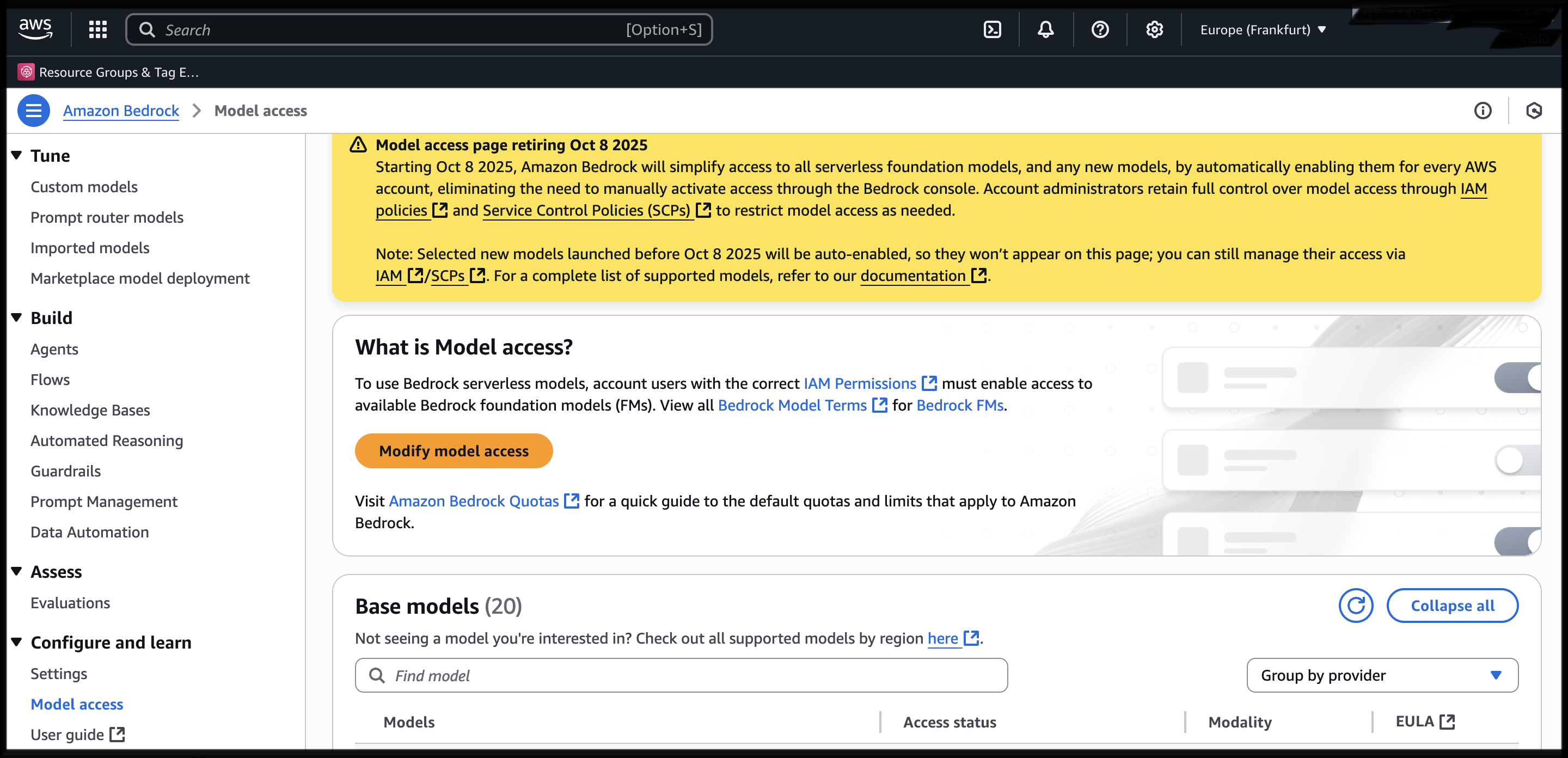 Bedrock Model Access Seite zum Beantragen von Modell-Berechtigungen
Bedrock Model Access Seite zum Beantragen von Modell-Berechtigungen
Inference Profile IDs verstehen #
Ein wichtiger Unterschied, der häufig zu Verwirrung führt, betrifft die Modell-Identifikatoren. Die IDs, die du im Konfigurationsskript verwendest, sind nicht die Model IDs aus dem “Model Catalog”, sondern die “Inference Profile IDs”. Diese findest du unter “Infer” > “Cross Region Inference” in der Bedrock-Konsole. Diese Unterscheidung ist entscheidend für die korrekte Funktion der Integration.
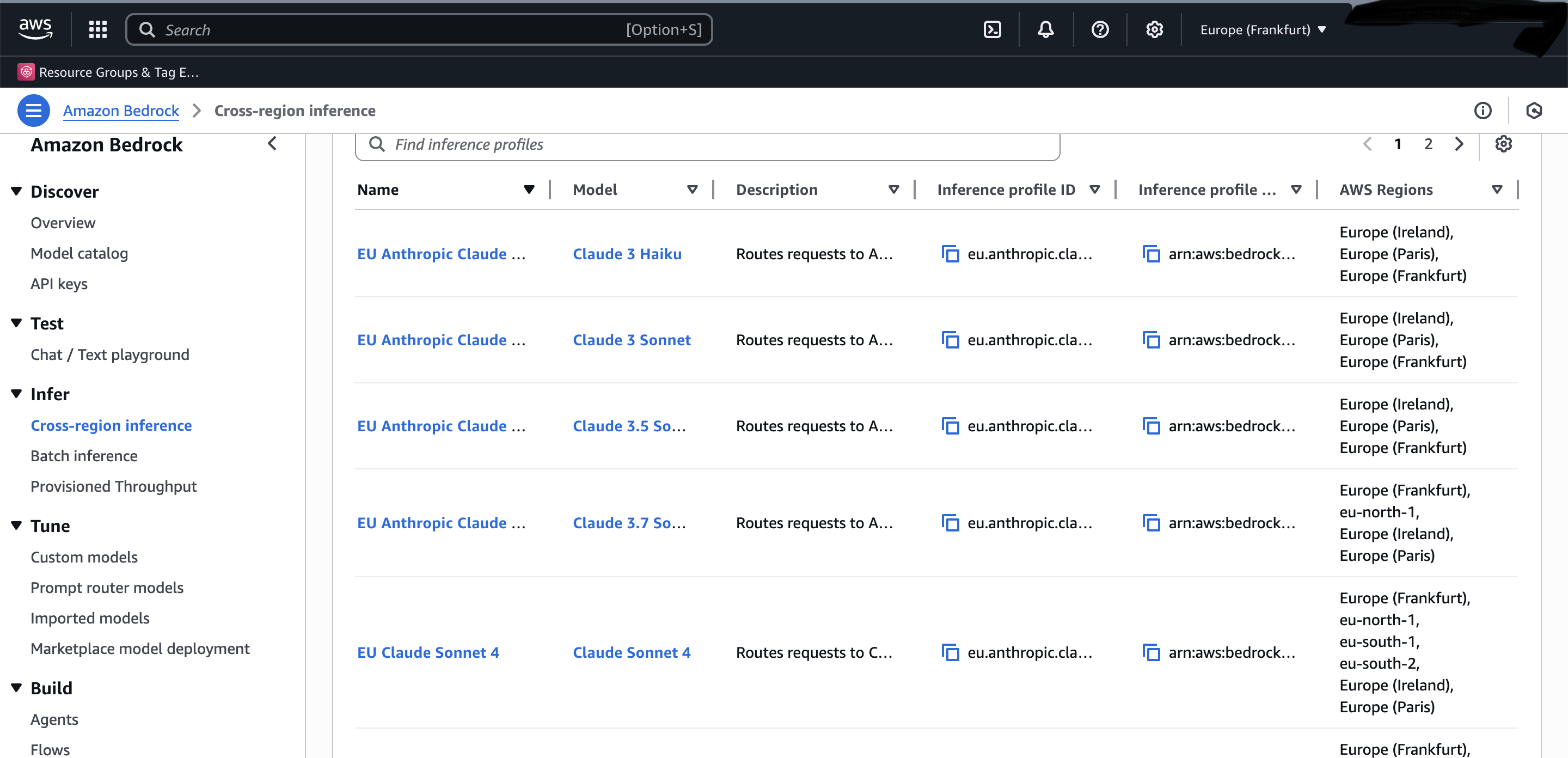 Cross Region Inference Seite mit den korrekten Inference Profile IDs
Cross Region Inference Seite mit den korrekten Inference Profile IDs
Claude Code aktivieren #
Nachdem du alle Vorbereitungen getroffen hast, ist es Zeit, Claude Code mit der Bedrock-Integration zu starten. Trage alle Werte nach deinen Wünschen in das obige Shell-Skript ein und speichere es als bedrock.sh. Dann führst du folgende Befehle aus:
source ./bedrock.sh
claude
Wenn alles geklappt hat, arbeitet Claude nun mit AWS Bedrock. Du merkst den Unterschied daran, dass die Modell-Auswahl jetzt aus deinen konfigurierten Bedrock-Modellen stammt und die Antworten über deine AWS-Infrastruktur verarbeitet werden.
Wichtige Hinweise zur Konfiguration #
Es finden sich eigentlich alle Hinweise in der Dokumentation von Anthropic, die oben verlinkt ist. Hier nochmal in Kürze das Wichtigste:
Token-Limits verstehen #
Die konfigurierten Token-Limits sind besonders wichtig für die praktische Nutzung. CLAUDE_CODE_MAX_OUTPUT_TOKENS=4096 bestimmt, wie ausführlich Claude antworten kann, während MAX_THINKING_TOKENS=1024 die interne “Denkzeit” des Modells begrenzt. Diese Werte haben sich in der Praxis für die meisten Entwicklungsaufgaben als geeignet erwiesen.
Prompt Caching #
Standardmäßig ist Prompt Caching aktiviert, was die Performance bei wiederholten ähnlichen Anfragen verbessert. Falls du aus irgendeinem Grund komplett frische Antworten benötigst, kannst du die auskommentierte Zeile DISABLE_PROMPT_CACHING=1 aktivieren.
Troubleshooting häufiger Probleme #
“Model not found” Fehler #
Wenn Claude eine Fehlermeldung bezüglich nicht gefundener Modelle ausgibt, überprüfe die Inference Profile IDs in deinem Skript. Diese ändern sich gelegentlich und müssen aus der aktuellen Bedrock-Konsole übernommen werden. Außerdem kann es vorteilhaft sein, weniger populäre oder aktuelle Modelle zu verwenden. So nutze ich mittlerweile eher Sonnet 3.7 als das neuere Sonnet 4, um Request Limits zu umgehen.
Berechtigungsfehler #
Sollten Berechtigungsfehler auftreten, überprüfe, ob der automatisch erstellte Benutzer wirklich die AmazonBedrockFullAccess Berechtigung erhalten hat. Manchmal dauert es einige Minuten, bis Berechtigungsänderungen wirksam werden.
Fazit #
Mit dieser Konfiguration ist Claude Code erfolgreich mit AWS Bedrock verbunden. Die initiale Einrichtung ist aufwendiger als die Standard-Claude-Nutzung, bietet aber mehr Flexibilität und Kontrolle.
In Unternehmensumgebungen mit Datenschutz- und Compliance-Anforderungen bietet diese Lösung praktische Vorteile: klare Kontrolle über den Verarbeitungsort der Daten, transparente Kostenstruktur und die Möglichkeit, zwischen verschiedenen Modellen zu wechseln.
Claude Code ist nun mit AWS Bedrock konfiguriert und kann über das Terminal genutzt werden. Du kannst mit verschiedenen Foundation Models experimentieren und die passende Konfiguration für deine Entwicklungsaufgaben finden.
Das ganze Vorgehen lässt sich auch einfach auf andere Agentic Coding Lösungen übertragen: Cline bspw. nutzt einen ganz ähnlichen Menchanismus: https://docs.cline.bot/provider-config/aws-bedrock/api-key.
Nachtrag #
Es kann sinnvoll sein, mit verschiedenen Modellen schnell und einfach zu experimentieren. Statt die Umgebungsvariablen dann bspw. in der .profile, .bashrc, .zshrc Datei zu setzen, habe ich das als Shellscript parat, welches dann das schöne Utility gum verwendet. Dann kann man fix sein gewünschtes Modell auswählen. Die ensprechenden Zeilen im bedrock.sh Script würden dann so aussehen:
# Interactive model selection using gum
export ANTHROPIC_MODEL=$(gum choose --header="Select main model:" \
"eu.anthropic.claude-3-7-sonnet-20250219-v1:0" \
"eu.anthropic.claude-sonnet-4-20250514-v1:0" \
"eu.anthropic.claude-3-5-sonnet-20240620-v1:0" \
"eu.mistral.pixtral-large-2502-v1:0" )
Viel Spass und happy coding!
Kommentare