Hi everyone, I’m happy to announce a new release of solrs, our asynchronous / non-blocking solr client for java/scala.
These are the most noteable features of the new release:
- Shard support: Optimize request routing if
_route_parameter is set (solrs/#44) - Optimize routing: Send updates to shard leader (solrs/#45)
- Add support for standard collection aliases (solrs/#46)
- Optimize routing according to
shards.preference=replica.type(solrs/#48)
In the following some of them and their underlying Solr features are explained in more detail.
Optimize request routing if _route_ parameter is set #
This is relevant if you’re indexing documents in different shards and want to query only documents from a certain shard.
The overall process in short is this:
- Assuming you’re using the
compositeIdrouter (the default), at index time you send documents with a prefixedid, where the prefix will be used to determine the shard a document is sent to. For example, in a multi-tenant application, if you’d want to co-locate documents of the same tenant in the same shard, you’d use the tenant id as prefix, e.g. for document “12345” belonging to “tenant1” you’d set the id totenant1!12345. - At query time, you add the
_route_parameter with the prefix to the query, e.g.q=some query&_route_=tenant1!. solrs then evaluates the_route_parameter, determines the shard which matching documents are stored in, and directly sends the query to one of the replicas of the shard.
If solrs wouldn’t do this (on client side), the Solr node / replica receiving the request would still take care of this and send the request to one of the responsible shard replicas. This however might involve an additional network roundtrip.
This is a visualization of a possible data flow without solrs taking the _route_ parameter into account:
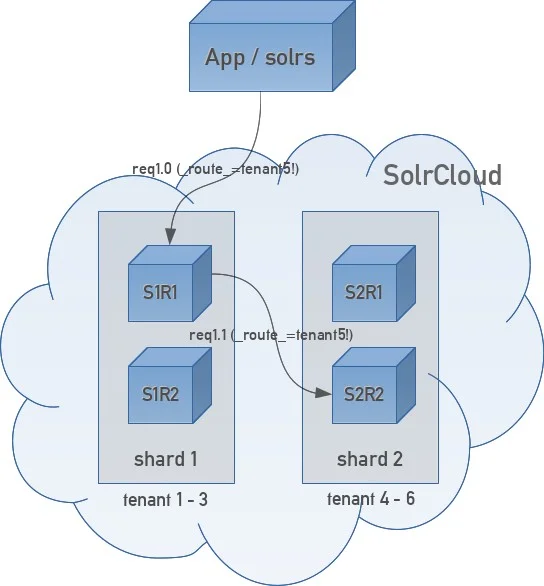
This figure shows a flow where the solrs internal/configured load balancer has randomly selected S1R1 as the node / replica as the destination host for the request. S1R1 then forwards the request to S2R2 (it could also have forwarded the request to S2R1 of course), because replicas of shard 2 are responsible for documents of tenant5. The response takes the same way back: from S2R2 via S1R1 to the client application.
Now that solrs evaluates the _route_ parameter already on application/client side, the request is always sent to a replica of the shard owning the matching documents, i.e. there’s never an unnecessary network roundtrip:
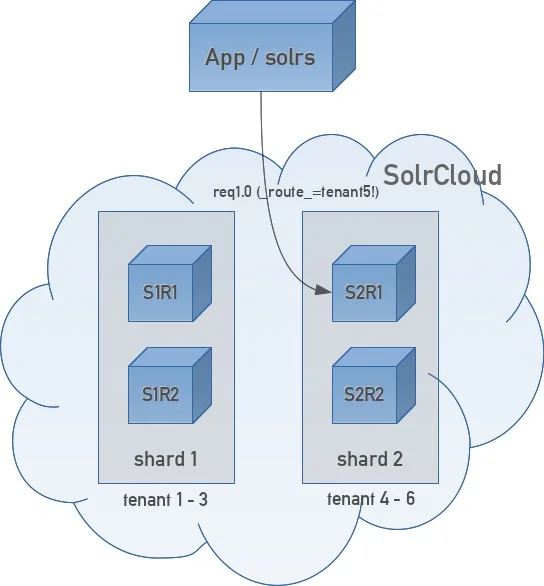
Note: with multiple shards, when you’re not setting the
_route_parameter, SolrCloud performs a distributed search, i.e. the Solr node hit by the client sends requests to randomly chosen replicas of every shard and returns the combined response - see also Solr Reference Guide: Distributed Requests.
Support standard collection aliases #
With the new release, solrs now also resolves standard collection aliases. From the CreateAlias documentation:
Standard aliases are simple: CREATEALIAS registers the alias name with the names of one or more collections provided by the command. If an existing alias exists, it is replaced/updated. A standard alias can serve to have the appearance of renaming a collection, and can be used to atomically swap which backing/underlying collection is “live” for various purposes.
A practical example is a full reindexing of a collection, e.g. because a new field was added, a data type was changed etc.
Taking a “products” collection as an example, one could do the following to support complete reindexing without affecting the ongoing usage of the original collection:
- When starting with the development of your application, create the collection “products_a”
- Let the indexing part of your application write to “products_a”.
- Create the collection alias “products_read” pointing to “products_a”
- Let the query part of your application query/read from “products_read”
Now, when you need to completely reindex the collection:
- Create a new collection “products_b”
- Spin up another instance of your indexer and let it write to “products_b” (the other instance continues to index “products_a”, since users shall still see the latest data)
- When “products_b” is completely indexed, you can update the “products_read” alias to point to “products_b”.
- Success!
Everything solrs does for this is to pull collection aliases from ZooKeeper to be able to resolve them - quite easy ;-)
Optimize Routing for Preferred Replica Types #
This adds support for a relatively new feature of SolrCloud (at the time of this writing), which was added in Solr 7: different types of replicas.
Pre SolrCloud: master/slave setup #
To explain this feature, let me look back in history: in pre-SolrCloud days we had master-slaves setups, where the master was indexed, and slaves replicated the index from the master (in the early days, this was done with rsync scripts - much fun of course ;-)). The user requests/queries were sent to a load balancer (nginx, haproxy etc), which routed requests to the slaves. The master was usually not included in the load balancing of query requests because it was too busy with indexing.
SolrCloud: new and (mostly) shiny #
Then came SolrCloud: it took away much of this manual setup (rsync, load balancer etc), Solr nodes got registered in ZooKeeper, the Solr client was smart enough balancing requests to appropriate Solr nodes, NRT (Near Real Time) searching was added and so on.
One drawback was this: every Solr node that stored a document had to index the document on its own (including the whole analysis chain, writing data to segments etc), i.e. every node did the same, hard work. In consequence, this also negatively affected the query performance. For some people, this was even a reason not to switch to SolrCloud!
Solr 7: Replica Types #
This issue got addressed with Solr 7, which introduced different replica types:
- NRT: the default replica type, which works as described above
- TLOG: maintains its own transaction log but does not index documents locally, instead it replicates the index from the shard leader
- PULL: only replicates the index from the leader
Only NRT and TLOG replicas can become leaders (when a TLOG replica becomes a shard leader it will at first process its transaction log, and then behaves like an NRT replica).
Also note that only certain combinations of replica types are supported, please consult the Replica Types documentation for this.
The different replica types now allow us to get back the positive aspects of our ancient master / slave setup, where one (or some) nodes do the hard indexing work, and other nodes can spent most of their time serving queries (of course we’re paying with reduced NRT searching capabilities).
Queries with Preferred Replica Types #
By default all replicas serve queries. However, the shards.preference parameter (introduced with Solr 7.4) can be used with the replica.type property to prefer replicas of a certain type. E.g. by adding the query parameter shards.preference=replica.type:PULL you can express that the request should be routed to a PULL replica.
solrs evaluates this parameter already on client side in order to save an unncecessary network roundtrip. Of course, if no matching replica is available, it still uses the other, available replicas for load balancing the request.
Note: in solrs, this selection of appropriate solr nodes for a query happens before load balancing, i.e. the load balancer distributes requests to appropriate ndoes according to its inherent logic (see also solrs load balancer documentation).
Finally #
The full list of changes in solrs 2.2.0 can be seen on github.
With the new solrs release the documentation is now available at inoio.github.io/solrs/, check it out to read more!
Kommentare